Входит в реестр отечественного ПО. Запись №26581 от 12.02.2025

Full-stack observability platform
Повысьте надежность с Sage Observability
Sage Observability — платформа наблюдаемости с ИИ и система мониторинга

Помогает реализовать лучшие
Полная прозрачность и управляемость системы
Помогает выявлять избыточные ресурсы и снижать издержки компании. Показывает эффекты от изменений в коде и приложениях
Помощь в принятии решений на основе данных в реальном времени
Помогает понимать первопричины проблем, быстро находить их и устранять. Сокращает MTTR — среднее время восстановления после сбоев
Соблюдение SLA
Проактивный мониторинг критических показателей и помощь в принятия мер до возникновения нарушений. Ваш SLO под контролем с Sage Observability
Больше, чем мониторинг ПО
Обзор топологии сервиса
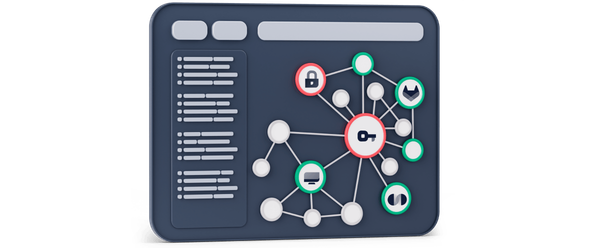
Подробная информация на каждом этапе на основе логов, метрик и трейсов
Автоматизация наблюдаемости для нативных облачных рабочих нагрузок и микросервисов
Понимание зависимостей внутри сервисов между
Улучшение совместной работы команд без аварийных созвонов
Выведите мониторинг и диагностику
Карта здоровья на страже
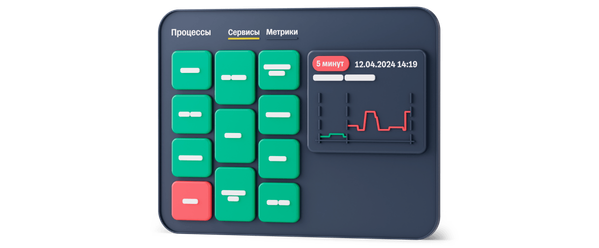
- Древовидный каталог сервисов
- Измерение метрик SLO
- Влияние систем друг на друга
- Корреляция данных для понимания уровня проблем
Предотвращение проблем с помощью искусственного интеллекта
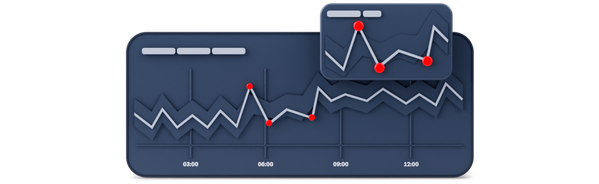
Обнаружение аномалий и оповещение о них в реальном времени
Нормализация показателей на основе исторических данных с учетом сезонности
Высокая точность.
Precision более 80%
О нас пишут
История клиента: как НСПК обеспечивает SLA 99,999% в национальном масштабе
Интервью Ивана Липкина, начальника управления прикладного мониторинга
«У нас нет сверхцели окупить платформу за счет внешних пользователей»
Интервью Игоря Маслова, директора разработки базовых технологий и инженерных практик Т‑Банк, о том, зачем нужна система мониторинга
Полезные материалы



Популярные вопросы о платформе наблюдаемости Sage Observability